
by Huenei IT Services | Nov 1, 2020 | Software development
In our previous article, “Key points about DevOps” we talked about what DevOps is and how it can help you optimize key elements in your company, such as shortening launch times, accelerating the realization of new products and services, and reducing costs. In this article, we will learn more about some good practices to start implementing this as soon as possible.
Doing a brief review, DevOps refers to the words ‘Development’ and ‘Operations’, it is a discipline that, despite being relatively recent, has allowed many companies and organizations to rethink their processes for more efficient and agile ones, managing to increase its competitiveness and efficiency.
Good practices on DevOps
For sure, there are countless benefits to the implementation of this methodology, taking into account that it does not imply an improvement in terms of technology or productivity in itself, but rather it allows to streamline the level of communication and collaboration between departments for optimal execution of operations, time and quality of delivery.
Adopting this new process does not happen overnight, and expected results could be negatively impacted if the company implements ineffectively.
At Huenei, we use this methodology to increase the effectiveness of our software development teams, as well as to improve the quality of the constant deliveries in Custom Software, Mobile Applications, involving it in Testing & QA and UX / UI processes. So we recommend following these practices:
1 – Continuous Integration Process (CPI)
This process is strongly supported by agile methodologies, its principle is to reduce implementation and deployment times, managing to divide a project into more parts, making gradual deliveries.
How this could help? As the team of developers constantly review changes in the repository code, they can more quickly detect any type of flaw and even constantly improve the execution of the operation. It is these early findings in the software life cycle that will help the development department to solve problems almost on the spot (and even prevent them).
2 – Continuous delivery
Arguably, this step accompanies the previous one, as starting with development, build, unit testing, static code analysis, and static analysis security testing in the PCI, it promotes automation of functional tests, integration, performance, and security, along with configuration management and deployment.
As the latter are critical areas for automation, and essential in a DevOps context, it is a type of practice that increases the amount of testing and verification at various stages in manual and automated code cycles.
In addition to allowing a team to build, test and launch the codebase in a faster and more frequent way, which by dividing it into cycles of smaller size and duration, speeds up the processes of organizations, allowing them to carry out more launches, reduce manual deployments and reduce the risks of production failures.
3 – Communication management
A key element in DevOps management, since its focus is on keeping all interested parties related to development, operation, and implementation informed, taking into account that we are integrating the tasks of different departments. Therefore, communication is essential and becomes a fundamental element for a total adoption, keeping everyone on the same page to involve them in the whole process, keep up to date with the organization and avoid doubts between them or the final products.
To apply the strategy correctly, it is vital to keep all the teams and members up to date, in this way it is guaranteed that the leaders of the organization (from the sales, production, and management departments) can be involved in the processes and guide the team development to make successful changes, from their perspectives and knowledge.
4 – Test automation
In software development, regular testing is essential to create quality code, which is vital to implement in a DevOps management, not only because it saves time by quickly completing tedious and time-consuming tasks, but also because it allows you to identify quickly early failures in pre-deployment processes.
This in itself is the core of agility and innovation, since the additional time that team members will have can be invested in tasks with greater added value or in monitoring the results of new processes, identifying failures and opportunities for improvement.
5 – Continuous monitoring
Like all cultural and work process changes, this requires close and continuous monitoring to anticipate and identify that all actions are being carried out correctly and that performance is as expected.
Continuous delivery of feedback from all members of the organization in real-time is vital to the organization; from the production team that runs the application to the end customer at the official launch stage. In this way, we ensure that the developer can benefit from all the valuable feedback on the end-user experience in the process and in turn, modify the code to meet the expectations of the end-user.
Conclusions
With an ever-evolving business environment and an ever-improving and growing technology landscape, organizations must seek to stay ahead, with DevOps they can increase the speed and quality of software implementations by improving communication and collaboration between parties. interested.
In themselves, these good practices allow creating a clear guide to guide any company, of any size and industry, to immerse themselves in the necessary cultural change, managing to increase productivity and efficiency through high-quality deliveries, adding transparency to their processes. and open collaboration across development and operations teams.
Know more about our process in the Software Development section.

by Huenei IT Services | Oct 15, 2020 | Software development, UX & UI Design
Introduction
In the previous articles, we talked about Hardware Acceleration with FPGAs, the Key concepts about acceleration with FPGA that they provide, and the Hardware acceleration applications with FPGAs. In this latest installment of the series, we will focus on Hardware Accelerated Libraries and Frameworks with FPGAs, which implies zero changes to the code of an application. We will review the different alternatives available, for Machine and Deep Learning applications, Image, and Video Processing, as well as Databases.
Options for development with FPGAs
Historically, working with FPGAs has always been associated with the need for a Hardware developer, mainly Electronic Engineers, and the use of tools and Hardware Description Languages (HDL), such as VHDL and Verilog (of the concurrent type in instead of sequential), very different from those used in the field of Software development. In recent years, a new type of application has appeared, acceleration in data centers, which aims to reduce the gap between the Hardware and Software domains, for the cases of computationally demanding algorithms, with the processing of large volumes of data.
Applying levels of abstraction, replacing the typical HDL with a subset of C / C ++ combined with OpenCL, took the development to a more familiar environment for a Software developer. Thus, basic blocks (primitives) are provided, for Mathematical, Statistical, Linear Algebra, and Digital Signal Processing (DSP) applications. However, this alternative still requires a deep knowledge of the hardware involved, to achieve significant accelerations and higher performance.
Secondly, there are accelerated libraries of specific domains, for solutions in Finance, Databases, Image, and Video Processing, Data Compression, Security, etc. They are of the plug-and-play type and can be invoked directly with an API from our applications, written in C / C ++ or Python, requiring the replacement of “common” libraries with accelerated versions.
Finally, we will describe the main ones in this article, there are open source libraries and frameworks, which were accelerated by third parties. This allows us, generally running one or more Docker instances (on-premise or in the cloud), to accelerate Machine Learning applications, Image processing, and Databases, among others, without the need to change the code of our application.
Machine learning
Without a doubt, one of the most disruptive technological advances in recent years has been Machine Learning. Hardware acceleration brings many benefits, due to the high level of parallelism and the enormous number of matrix operations required. They are seen both in the training phase of the model (reducing times from days to hours or minutes) and in the inference phase, enabling real-time applications.
Here is a small list of the accelerated options available:

TensorFlow is a platform for building and training neural networks, using graphs. Created by Google, it is one of the leading Deep Learning frameworks.

Keras is a high-level API for neural networks written in Python. It works alone or as an interface to frameworks such as TensorFlow (with whom it is usually used) or Theano. It was developed to facilitate a quick experimentation process, it provides a very smooth learning curve.

PyTorch is a Python library designed to perform numerical calculations via tension programming. Mainly focused on the development of neural networks.

Deep Learning Framework noted for its scalability, modularity and high-speed data processing.

Scikit-learn is a library for math, science, and engineering. Includes modules for statistics, optimization, integrals, linear algebra, signal and image processing, and much more. Rely on Numpy, for fast handling of N-dimensional matrices.

XGBoost (Extreme Gradient Boosting), is one of the most used ML libraries, very efficient, flexible and portable.

Spark MLlib is Apache Spark’s ML library, with scaled and parallelized algorithms, taking advantage of the power of Spark. It includes the most common ML algorithms: Classification, Regression, Clustering, Collaborative Filters, Dimension Reduction, Decision Trees, and Recommendation. It can batch and stream. It also allows you to build, evaluate, and tune ML Pipelines.
Image and Video Processing
Image and Video Processing is another of the areas most benefited from hardware acceleration, making it possible to work in real-time on tasks such as video transcoding, live streaming, and image processing. Combined with Deep Learning, it is widely used in applications such as medical diagnostics, facial recognition, autonomous vehicles, smart stores, etc.

The most important library for Computer Vision and Image and Video Processing is OpenCV, open source, with more than 2500 functions available. There is an accelerated version of its main methods, adding more version after version.

For Video Processing, in tasks such as Transcoding, Encoding, Decoding and filtering, FFmpeg is one of the most used tools. There are accelerated plugins, for example for decoding and encoding H.264 and other formats. In addition, it supports the development of its own accelerated plugins.
Databases and analytics
Databases and Analytics receive increasingly complex workloads, mainly due to advances in Machine Learning, which forces an evolution of the Data Center. Hardware acceleration provides solutions to computing (for example with database engines that work at least 3 times faster) and storage (via SSD disks that incorporate FPGAs between their circuits, with direct access to data processing). the data). Some of the Accelerated Databases, or in the process of being so, mainly Open Source both SQL and NoSQL, are PostgreSQL, Mysql, Cassandra, and MongoDB.
In these cases, generally what is accelerated are the more complex low-level algorithms, such as data compression, compaction, aspects related to networking, storage, and integration with the storage medium. The accelerations reported are in the order of 3 to 10 times faster, which compared to improvements of up to 1500 times in ML algorithms may seem little, but they are very important for the reduction of costs associated with the data center.
Conclusions
Throughout this series of 4 articles, we learned what a device-level FPGA is, how acceleration is achieved when we are in the presence of a possible case that takes advantage of them (computationally complex algorithms, with large volumes of data). General cases of your application and particular solutions, ready to use without code changes.
How can Huenei help your business with Hardware Acceleration with FPGAs?

Infrastructure: Definition, acquisition and start-up (Cloud & On-promise).

Consulting: Consulting and deployment of available frameworks, to obtain acceleration without changes in the code.

Development: Adaptation of existing software through the use of accelerated libraries, to increase its performance.

by Huenei IT Services | Oct 1, 2020 | Mobility
Microservices architecture, or simply microservices, is a distinctive method of mobile development and software systems that tries to focus on building single-function modules with well-defined interfaces and operations, which is why it is considered a trend that could benefit to many companies since it is oriented to provide services and is composed of freely coupled elements that have delimited contexts.
The term “freely coupled” means that you can update the services independently, this update does not require changing any other services. In fact, if you have a bunch of small and specialized services but to make a change to them you have to update them together, then it can’t be called microservices architecture as they are not flexibly coupled.
In other words, they are a granular architectural pattern that separates parts of an application into small independent services, furthermore, in mobile and software development it is an architectural style that structures an application as a collection of services that is constantly supported and checked weakly. independently docked and deployable.
In addition to being organized around business capabilities and their multiple benefits, it is believed that 90% of all new applications will have a microservices architecture to enhance the ability to design, debug, update, and leverage third-party code.
1) Create a separate data store for each microservice
First of all, don’t use the same data store for the backend when you want to implement it or transition to this type of architecture.
For this, it allows the team of each microservice to choose the database that best suits the service and that can be stored in a single data space, this allows the writing of different teams and that they can share database structures. data, thus reducing duplication of work.
Keeping data separate can make data management more complicated, because separate storage systems can fail or slow down at times of synchronization, becoming inconsistent and limiting scalability.
2) Keep the code at a similar level of maturity
This practice recommends keeping all the code at a similar level of maturity and stability, i.e. if you need to add or rewrite some of the code in this type of well-implemented architecture, the best approach is usually to create a new microservice for the new code or modified, leaving the existing microservice in place.
In this way, you can repeatedly implement and test the new code until it is error-free and as efficient as possible, with no risk of failure or performance degradation in the existing microservice, this process is known as the immutable infrastructure principle.
Thus, after verifying that this new microservice is as stable as the original, allowing them to merge again if they really perform a single function together, or if there are other efficiencies when combining them.
3) Make a separate compilation for each microservice
This is one of the best-recommended practices when designing such an architecture for mobile or software development, as it encourages a separate compilation for each microservice so that you can extract component files from the repository in the revision levels appropriate for him.
This sometimes leads to the situation where several of this type extract a similar set of files, but at different revision levels, that can make it more difficult to clean up the codebase by removing old versions of files (because you should check more carefully that a patch is no longer being used), but that’s an acceptable trade-off for how easy it is to add new files as you build new microservices.
4) Deploy in containers
Deploying microservices in containers is important because it means you only need one tool to implement it all.
As long as the microservice is in a container, the tool knows how to implement it, no matter what the container is.
5) Treat servers as interchangeable members
This practice recommends treating servers, particularly those running client-oriented code, as interchangeable members of a group.
That is, they all perform the same functions, so you don’t need to worry about them individually, your only concern is that they exist enough to produce the amount of work you need, and you can use the automatic scale to adjust the numbers up and down.
That way, if one stops working, it is automatically replaced by another.
6) Use ‘defense in depth’ to prioritize key services
After identifying which are your most sensitive services, you apply several different layers of security so that a potential attacker who can exploit one of their security layers still has to find a way to defeat all their other defenses in your critical services.
In general, this is easier said than done, but there are several resources available, the good news is that these types of architectures facilitate the adoption of this strategy in a very granular and strategic way, by focusing your security resources and efforts on microservices. specific, increasing the diversification of the security layers you want to adopt in each of them.
7) Use automatic security updates
Every time a part of your system is updated, you should make sure to detect any problems as soon as possible and in as much detail as possible.
To do this, implement this practice to ensure that your platform is mainly “atomic”, that is, everything must be wrapped in containers so testing your application with an updated library or a language version is just a matter of wrapping a different container All around you, so if the operation fails, reversing everything will be quite easy and, most importantly, it can be automated.
Conclusions
Unlike the monolith architecture, designing and implementing microservices correctly can be somewhat challenging and difficult, but since it provides a decentralized solution for different problems for mobile development and software development, defining the set of best practices it’s not only important but also crucial.
Thus, not only is a robust bulletproof system created, but a lot of disasters are prevented that could be highly counterproductive.
In itself, as a microservice is capable of encompassing central business capacity and at the same time adhering to fundamental design principles and objectives, it becomes a true digital asset, not only for mobile and software development but also because It is ideal to add value to the company, being able to use it successfully in multiple contexts and processes, both transactional and communicational.
Learn more about our Mobile Development processes in our section.

by Huenei IT Services | Sep 15, 2020 | UX & UI Design
User Story Mapping is a visual exercise often performed by product managers and their application development or web development teams to define the work that will create the most enjoyable, optimal, and agile user experience.
In other words, it is an agile and powerful product design method that is used to create a user-centered product, that is, they are the visual aid to build a shared understanding between the members of a web or application development project, to learn how to develop a successful design process.
This type of method is used to improve the understanding of the teams of their clients and to prioritize the work of all the development teams, where they create a dynamic diagram of the interactions of a representative user with the product, evaluating what steps the greater benefit for the user and prioritizing what should be built next.
In this case, this process always begins with the understanding of a problem and at the same time, knowing the user’s objectives, allowing to centrally draw the steps that this user will go through to achieve their objectives and thus narrate a natural narrative flow. user journey to explore all user activity easily.
Basic elements of a User Story Mapping
In order to know how to elaborate a User Story Mapping, it is important to know what are the structural elements that organize this type of design, that is why in Huenei IT Services we first present their names and in this way, you will be able to better understand each of the steps.
Next, the basic elements of this type of design, which, when organized in two dimensions (the vertical denotes priority, while the horizontal represents the steps a user takes to perform actions in the system, also known as the user’s journey or Buyer’s journey, allow a simple and clear reading of the general structure:
1) Backbone
In English, you will find it as “Backbone” and this is the base of the map, it consists of epics or themes that describe the general activities of the user in the system, such as “Search Products”, in this case, the epics are organized in horizontal order, as they represent the steps a user takes while interacting with the product, which is basically a simple visualization of the user’s journey.
In order to better understand the concepts of epics and epics within this structure, it is important to know that the epic represents the User Story so large as to be able to accommodate multiple stories and the epic refers to when multiple epics are held in and of themselves.
2) User Stories
Also known as “Stories” and unlike a flat backlog structure, user stories are organized in vertical and horizontal dimensions.
In this case, they are grouped into corresponding epics, which describe more specific tasks that a user may require. If an epic describes a search phase, it can include stories like basic search, filter products, advanced search, etc. When stories are vertically prioritized, they can be broken into releases.
3) Users
It refers to the fictitious people who will use the product, that is, they will carry out the steps described in the user stories.
This element is provided by UX specialists or by the marketing department and will serve as the basis for the map, since not knowing who the users are, it will be impossible to understand the epics of the product and, therefore, will lose the whole point of the story mapping.
By having user people or talking to UX staff, you can define who are the people who will perform certain actions in the system.
Guide to develop a User Story Mapping
Making a User Story Mapping will be as varied and different according to the size of your team, the scope and duration of a project, and the maturity phase of the product.
However, this is a process that must be carried out, especially when optimal results are expected from start to finish, and for this, the best time to start making it is when you have met all the product requirements and defined the equipment to the project, already knowing what the backbone is, the stories of the users and the users, it is easier to carry out these steps.
Step 1: Set the objectives of the project
First of all, focus on the potential customers of your business and summarize what goals these customers can achieve through the use of your product, write each of the goals and organize them in the logical order, you can use stickers or do it on aboard.
Step 2: Create the trip map
After collecting the objectives, it accounts for the user’s journey to achieving the objective, identifies the steps and avoids errors by faithfully following the narrative flow, to organize it closer to reality, placing the steps on the second line, step by step.
Step 3: Find solutions
Through this process, you create “user stories”, initially, you can use the following template: As a user – I Want This Goal – So the step is this.
Brainstorm with your team to collect most of the possible solutions and put all the user stories in the related steps.
Step 4: Organize the tasks according to their priority
If the brainstorming team was successful, then the story map should be full of great ideas, however, these stories cannot be run at the same time so in this step, you determine the different priority levels.
Identify the most common behavior or basic solution to the problem, so you organize user stories by priority and put the most important one at the top of the column.
Discussing customer priorities is crucial, so make sure you stay connected to your partners.
Step 5: Determine the launch structure
To do this, it initially indicates the smallest part of the product, the minimum viable product, and tries to complete the user’s journey starting with the most common or easiest tasks to carry out.
In this part, just focus on completing at least one user journey, after that, organize the rest of the accumulated work into tangible pieces by drawing horizontal lines between tasks.
By adding estimates to user stories, you can plan and schedule the entire development process version by version.
All the steps in this guide to elaborate a User Story Mapping are important, especially the latter represents one of the most important pieces of information in the whole process because it not only represents a crucial phase of the map but also because it will help you calculate the delivery time and costs.
Conclusions
The most important thing is to always keep in mind the end-user experience since their level of satisfaction and adoption are key in the success of the development, as well as in the fulfillment of the business objectives.
If you need to know more about User Story Mapping, we recommend you visit our services page UX / UI Design Services .

by Huenei IT Services | Sep 1, 2020 | Software development
We previously learned about the benefits of Hardware Acceleration with FPGAs, as well as a few Key concepts about acceleration with FPGAs for companies and teams. In this article, we will learn about the applications that typically benefit from employing this technology.
First, we will compare distributed and heterogeneous computing, highlighting the role of FPGAs in data centers. Then, we will present the most widespread uses of Acceleration with FPGAs, such as Machine Learning, Image and Video Processing, Databases, etc.
Distributed vs. Heterogeneous Computing
Over the past 10 years, we have witnessed an exponential growth in the generation of data. This in part thanks to the rise and popularity of electronic devices, such as cell phones, Internet of Things (IoT), wearable devices (smart-watches), among many others.
At the same time, the consumption of higher quality content by users has been increasing, a clear example being the case of television and/or streaming services, which have gradually increased the quality of content, resulting in a greater demand for data.
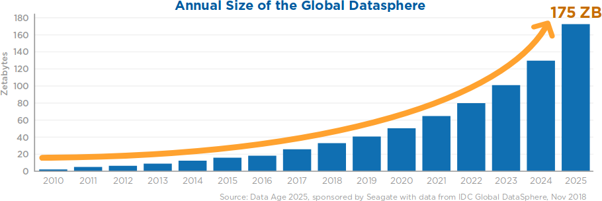
This growth in the creation/consumption of data brought the appearance of new computationally demanding applications, capable of both leveraging data and aiding in their processing.
However, an issue can arise with processing times, which directly affects the user experience, making the solution impractical. This raises the question: how can we reduce execution times to make the proposed solutions more viable?
One of the solutions consists of using Distributed Computing, where more than one computer is interconnected to a network to distribute the workload. Under this model, the maximum theoretical acceleration to be obtained is equal to the number of machines added in the data processing. Although it is a viable solution, it offers the problem that the time involved in distributing and transmitting data over the network must be considered.
For example, if we want to reduce data processing time to one third, we would have to configure up to four computers, which would skyrocket energy costs and the necessary physical space.
Another alternative is to use Heterogeneous Computing. In addition to using processors (CPUs) for general purposes, this method seeks to improve the performance of one computer by adding specialized processing capabilities to perform particular tasks.
This is where general-purpose graphics cards (GPGPUs) or programmable logic cards (FPGAs) are used, one of the main differences being that the former have a fixed architecture, while the latter are fully adaptable to any workload, in addition to a smaller energy consumption (since they generate the exact Hardware to be used, among other reasons).
Unlike Distributed Computing, in Heterogeneous Computing, acceleration will depend on the type of application and the architecture developed. For example, in the case of databases, the acceleration may have a lower frequency than a Machine Learning inference case (which can be accelerated by hundreds of times); another example would be the case of financial algorithms, where the acceleration rate is given in the thousands.
Additionally, instead of adding computers, boards are simply added in PCIe slots, saving resources, storage capacity, and energy consumption. This results in a lower Total Cost of Ownership (TCO).
FPGA-based accelerator cards have become an excellent accesory for data centers, available both on-premise (own servers) and in cloud services like Amazon, Azure, and Nimbix, among others.
Applications that benefit from hardware acceleration with FPGAs
In principle, any application involving complex algorithms with large volumes of data, where processing time is long enough to mitigate access to the card, is a candidate for acceleration. Besides, the process must be carried out through parallelization. Some of the typical solutions for FPGAs which respond to these characteristics are:

One of the most disruptive techniques in recent years has been Machine Learning (ML). Hardware acceleration can bring many benefits due to the high level of parallelism and the huge number of matrix operations required. These can be seen both in the training phase of the model (reducing this time from days to hours or minutes) and in the inference phase, enabling the use of real-time applications, like fraud detection, real-time video recognition, voice recognition, etc.

Image and Video Processing is one of the areas most benefited by acceleration, making it possible to work in real-time on tasks such as video transcoding, live streaming, and image processing. It is used in applications such as medical diagnostics, facial recognition, autonomous vehicles, smart stores, augmented reality, etc.

Databases and Analytics receive increasingly complex workloads due to advances in ML, forcing an evolution of data centers. Hardware acceleration provides solutions to computing (for example, with accelerators that, without touching code, accelerate PostgreSQL between 5-50X or Apache Spark up to 30x) and storage (via smart SSDs with FPGAs).
The large volumes of data to be processed require faster and more efficient storage systems. By moving information processing (compression, encryption, indexing) as close as possible to where the data resides, bottlenecks are reduced, freeing up the processor and reducing system power requirements.

Something similar happens with Network Acceleration, where information processing (compression, encryption, filtering, packet inspection, switching, and virtual routing) moves to where the data enters or leaves the system.

High-Performance Computing (HPC) is the practice of adding more computing power, in such a way as to deliver much higher performance than a conventional PC, to solve major problems in science and engineering. It includes everything from Human Genome sequencing to climate modeling.

In the case of Financial Technology, time is key to reducing risks, making informed business decisions, and providing differentiated financial services. Processes such as modeling, negotiation, evaluation, risk management, among others, can be accelerated.

With hardware acceleration, Tools and Services can be offered to process information in real-time, helping automate designs and reducing development times.
Summary
Making a brief comparison between the models, in Distributed Computing, more than one computer is interconnected in a network and the workload is distributed among all of them. This model, used for example by Apache Spark, is highly scalable but has a high energy consumption and requires a large physical space, which increases proportionally.
As for Heterogeneous Computing, the performance of one computer is improved by adding hardware (for example, via graphics cards such as GPGPUs or FPGAs), adding specialized processing capabilities. This makes it possible to obtain acceleration rates that depend on the type of application, but that can be, in some cases, between 1-10X (for example, when using Databases) up to hundreds or thousands of times when using Machine Learning.
Through a profiling and validation analysis of the feasibility of parallelizing the different processes and solutions, we can determine if FPGA Hardware Acceleration is the ideal solution for your company, especially when working with complex algorithms and large data volumes.
In this way, your business can improve user satisfaction rates by offering a faster and smoother experience with reduced processing times; additionally, and thanks to the reduction of TCO, your budget control can be optimized.
