
by Huenei IT Services | Mar 26, 2021 | Infra, Process & Management
Data has become a vital element for digital companies, and a key competitive advantage. However, the volume of data that organizations currently have to manage is very heterogeneous and its growth rate is exponential. This creates a need for storage and analysis solutions that offer scalability, speed and flexibility to help manage these massive data volumes. How can you store and access data quickly while maintaining cost effectiveness? A Data Lake is a modern answer to this problem.
This series of articles will look into the concept of Data Lakes, the benefits they provide, and how we can implement them through Amazon Web Services (AWS).
What is a Data Lake?
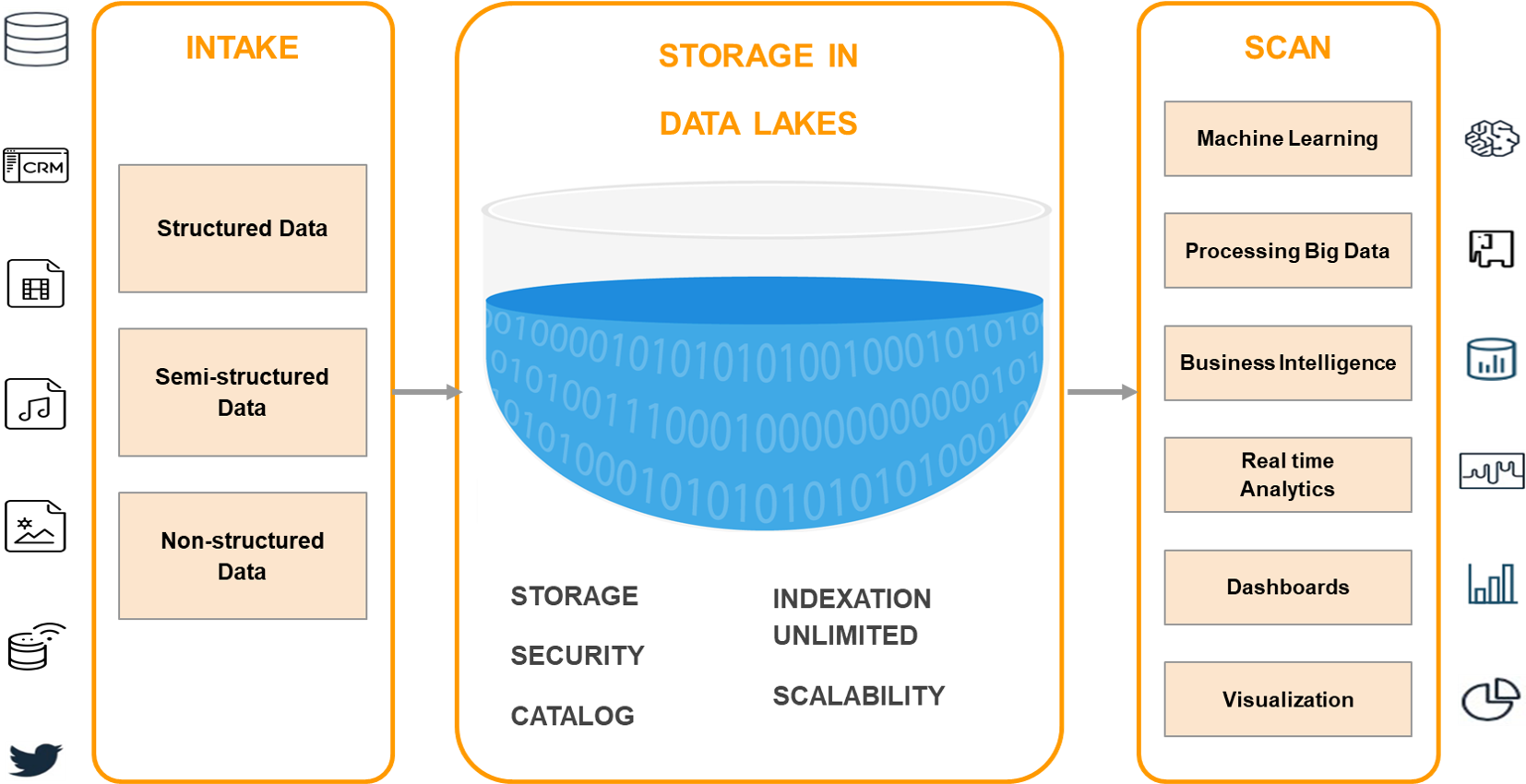
A Data Lake is a centralized storage repository that can store all types of structured or unstructured data at any scale in raw format until needed. When a business question arises, the relevant information can be obtained and different types of scans can be carried out through dashboards, visualizations, Big Data processing and machine learning to guide better decision-making.
A Data Lake can store data as is, without having to structure it first, with little or no processing, in its native formats, such as JSON, XML, CSV, or text. It can store file types: images, audio, video, weblogs, data from sensors, IoT devices, social networks, etc. Some file formats are better than others, such as Apache Parquet, which is a compressed column format that provides very efficient storage. Compression saves disk space and I/O access, while the format allows the query engine to scan only the relevant columns, reducing column time and costs.
Using a distributed file system (DFS), such as AWS S3, allows to store more data at a lower cost, providing multiple benefits:
- Data replication
- Very high availability
- Low costs at different price ranges and multiple types of storage depending on the recovery time (from immediate access to several hours)
- Retention policies, allowing to specify how long to keep data before it is automatically deleted
Data Lake versus Data Warehouse
Data Lakes and Data Warehouses are two different strategies for storing Big Data, in both cases without being tied to a specific technology. The main difference between them is that, in a Data Warehouse, the data scheme is pre-established; you must create a scheme and schedule your queries. Powered by multiple online transactional applications, data has to be converted via ETL (extract, transform and load) to conform to the predefined scheme in the data warehouse. In contrast, a Data Lake can host structured, semi-structured, and unstructured data and has no default scheme. Data is collected in its natural state, requires little or no processing when saved, and the scheme is created during reading to meet the processing needs of the organization.
Data Lakes are a more flexible solution adapted to users with more technical profiles, with advanced analytical needs, such as Data Scientists, since a level of skill is needed to be able to classify the large amount of raw data and easily extract its meaning. A data warehouse focuses more on Business Analytics users, to support business inquiries from specific internal groups (Sales, Marketing, etc.), by owning the data already curated and coming from the company’s operating systems. In turn, Data Lakes often receive both relational and non-relational data from IoT devices, social media, mobile apps, and corporate apps.
When it comes to data quality, Data Warehouses are highly curated, reliable, and considered the core version of the truth. On the other hand, Data Lakes are less reliable since data could come from any source in any condition, be it curated or not.
A Data Warehouse is a database optimized to analyze relational data, coming from transactional systems and business line applications. They are usually very expensive for large volumes of data, although they offer faster query times and higher performance. Data Lakes, by contrast, are designed with a low storage cost in mind.
Some of the legitimate criticism Data Lakes have received is:
- It is still an emerging technology compared to the strong maturity model of a Data Warehouse, which has been in the market for several years.
- Data Lakes could become a “swamp”. If an organization has poor management and governance practices, it can lose track of what exists at the “bottom” of the lake, causing it to deteriorate and making it uncontrolled and inaccessible.
Due to these differences, organizations can choose to use both a Data Warehouse and a Data Lake in a hybrid deployment. One possible reason would be adding new sources or using the Data Lake as a repository for everything that is no longer needed in the main data warehouse. Data Lakes are often an addition or evolution to an organization’s current data management structure rather than a replacement. Data Analysts can use more structured views of the data to get the answers they need and, at the same time, Data Science can “go to the lake” and work with all the raw information as necessary.
Data Lake Architecture
The physical architecture of a Data Lake may vary, since it is a strategy applicable by multiple technologies and providers (Hadoop, Amazon, Microsoft Azure, Google Cloud). However, there are 3 principles that make it stand out from other Big Data storage methods, and they make up its basic architecture:
- No data is rejected. They are loaded from multiple source systems and preserved.
- Data is stored in an untransformed or nearly untransformed condition, as received from the source.
- Data is transformed and a scheme is adapted during analysis.
While information is largely unstructured or geared to answering specific questions, it must be organized as to ensure that the Data Lake is functional and healthy. Some of these features include:
- Tags and/or metadata for classification, which can include type, content, usage scenarios, and groups of potential users.
- A hierarchy of files with naming conventions.
- An indexed and searchable Data Catalog.
Conclusions
Data Lakes are becoming increasingly important to business data strategies. They respond much better to today’s reality: much larger volumes and types of data, higher user expectations and a greater variety of analytics, both business and predictive. Both Data Warehouses and Data Lakes are intended to coexist with companies that want to base their decisions on data. Both are complementary, not substitute, and can help any business to better understand both markets and customers, as well as promote digital transformation efforts.
Our next article will delve into how we can use Amazon Web Services and its open, secure, scalable, and cost-effective infrastructure to build Data Lakes and analytics on top of them.

by Huenei IT Services | Dec 30, 2020 | Software development
In previous articles, we went through an “Introduction to Business Blockchain” and summarized the “Technical Characteristics of Blockchain“. In this latest installment of the series, we will focus on the most widespread usage patterns and analyze a flagship case of Supply Chain, aside from Decentralized Finance (DeFi).
Use cases
When analyzing the use that is being given to Blockchain in the corporate sphere, it is possible to detect some common and recurring usage patterns:
Banking and Finance
DeFi includes digital assets, protocols, smart contracts, and Distributed Applications (dApps). It is the original use case and it involves everything related to cryptocurrencies and the financial world in general. We can mention Ripple, a global network of electronic payments, with the support of institutions such as Santander, Itaú, American Express, among others. Another example is Santander One Pay FX, a Blockchain network to streamline international transfers.
Supply Chains
After DeFi, it is the most popular use case. Blockchain allows the complete traceability of any good, from the producer to the final consumer, be it raw materials, food or medicine, in the case of Pharmacovigilance. IoT (Internet-of-Things) devices are also commonly used for automated registration in different stages of a workflow. There are already numerous success stories in several industries, such as food (Walmart and later IBM Food Trust is the most emblematic cases that we will analyze), pharmaceuticals (Novartis), automotive (Ford, BMW, Tesla), among others.
Audit
Leveraging immutability, one of the distinctive characteristics of Blockchain, stored transactions cannot be modified at a later stage, which allows a complete audit of critical information. This is used in Fraud Prevention, Claims Management, Insurance (BBVA), Health (EHR, Medical Records Management with projects such as MedicalChain & MedRec) and Pharmacovigilance (for example, the Pharmaledger project).
Public Administration
Currently, many governments around the world are conducting research on how to take advantage of the benefits of Blockchain in Citizen Identity systems, voting, budgets, and public tenders to increase the efficiency and transparency of the State. Latin America strives not to be left behind, and many developments are already underway. Argentina has several projects on the Argentine Federal Blockchain network (BFA), such as sessions of Deputies in Congress, Central Bank Complaints Registry, Citizen Files in the City of Buenos Aires, among others. Brazil, Peru, and Uruguay are also making strides. Globally, the United Arab Emirates, especially Dubai, plans to become a fully Blockchain-governed, paperless city by 2021 through the Smart Dubai project.
Certified Information
Many institutions use Blockchain for the certification and validation of all types of workforce, personal and educational records (Citizen Files in Buenos Aires).
Data Sharing
In a new human-centered model, people take control of their information, centralize it to decide who can access their data. For example, patients own their complete Medical Records and can give access to them to the professional who needs them (EHR MedicalChain & MedRec), citizens can share their credentials (Sovereign Digital Identity projects in Argentina, Data Sharing Toolkit in UAE, etc.)
Asset Tokenization
Blockchain is used for the management of digital assets, in the exchange of all kinds of goods between individuals or entities, such as tickets to shows (UEFA & Ticketmaster), loyalty program points (American Express), real estate (UK Land Registry in England), etc.
Copyright
This technology is used to create records with date, time and authorship, to optimize the management of Intellectual Property. Used by Kodak with Photo Tracking and Spotify Mediachain to accurately attribute songs to creators.
Use Case: Food Supply Chain
Among the many use cases of Blockchain, its application in a supply chain is one of the most emblematic, and developments can be seen in all industries.
In a food supply chain, multiple actors have involved: farmers, ranchers, suppliers, cooperatives, packers, transporters, exporters, importers, wholesalers, retailers, and, lastly, the final consumer. Health safety is one of the biggest concerns in the food industry. Like the pharmaceutical industry, the food sector faces increased regulatory pressure from government agencies.
Walmart is a pioneer in this field, having tried several times to create a system that allows for transparency and complete traceability in the food system, which was finally accomplished in 2016. Blockchain, with its decentralized and shared ledger, seemed tailor-made for the Company’s needs. Walmart began working with its technology partner IBM on a food traceability system based on Hyperledger Fabric. For the Chinese pork industry, it allowed uploading certificates of authenticity, which gives more confidence to a system where certificates used to be a serious problem. For mangoes in the United States, the time needed to trace their origin went from 7 days… to 2 seconds!
The newly developed system allows users to know the exact origin of each item (to control disease outbreaks) in seconds, discarding only products from the affected farms. For example, it allows customers to scan a jar of baby food to see where it was made, tracing all the ingredients back to the farms.
As a result, the IBM Food Trust was launched, involving multiple companies such as Nestlé and Unilever. This platform allows access to the following information in real-time:
- Inventory at each location.
- The freshness of each product.
- Average time on the shelf.
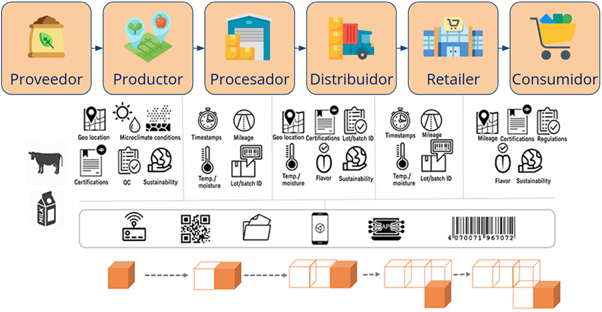
Blockchain allows a product to be traced through the different industrial, logistical, and administrative operations, from the beginning of the process to the end, and vice versa. In this way, a secure and distributed record can be consolidated with the history of every actor in the chain, their exchanges during the production and distribution processes of the product, managing information in a reliable and tamper-proof manner. As automatic transactions have no intermediaries (such as banks), they allow for faster settlements under conditions set forth in smart contracts.
IoT and Blockchain combined offer great benefits. Sensors can capture a variety of data in manufacturing facilities or transportation, transmitting all the information to a centralized repository in real-time. In turn, Managers can gain a multitude of new insights into material usage, transport conditions, etc., and apply them in planning/optimization efforts. Producers can use IoT to register the entire growth process of the product (food, pesticides, humidity, storage, location). Carriers can automatically ensure that products are moved under the right conditions of temperature, humidity, etc., thus achieving better visibility into overall logistics.
Conclusions
Throughout this 3-articles series, we learned about Blockchain technology and its application in the business environment. We were able to understand its basic operation, the most prominent platforms and its current application in many industries.
How can Huenei help your business with Blockchain?
- Consultancy: We help you choose the technology that best suits your needs.
- Architecture: Definition, deployment, and start-up.
- Development: Smart contracts and complete systems based on Blockchain.
We work with you from the planning and definition of requirements to the start-up of the final project.

by Huenei IT Services | Dec 15, 2020 | Software development
The two main problems that software development projects usually face are delays in delivery dates and exceeding the proposed budget; both of these issues arise when teams fail to adequately calculate the necessary resources. This results not only in a commercial failure but also in a drop in companies’ satisfaction rates.
Therefore, it is vital that companies know how to effectively conduct a digital product discovery before moving forward in laying the foundation for a project. This is why the discovery phase is crucial to mitigate the aforementioned risks, regardless of whether the project is part of a large-scale business system or if it is a turnkey development.
Both outsourcing companies and clients need to give the necessary importance to this stage, as it will improve the quality of the project and the expected final result.
What is the Discovery process?
It is the process of gathering and analyzing information about a project, its target market, audience, among other factors. It is intended to ensure a complete and deep understanding of the goals, scope, and limitations in order to help understand end-users along with their needs and requirements.
Additionally, it defines a set time to collect this information, thus allowing all members of the development team, as well as the client, to meet and create a shared understanding of the project goals. However, this goes beyond a mere kick-off meeting. This collaborative vision is about all teams being able to guide, from their point of view, more values and characteristics to ensure the execution of the project, in turn providing commercial value.
Who is involved in the Discovery phase in Software development?
Ideally, as many team members as possible should take part, from programmers and testers to functional analysts, from a more technical and specialized point of view.
On the other hand, team members from the client must also be part of it, since they have a greater knowledge of both the industry and their own consumers, offering valuable information that can increase user satisfaction rates. A list of teams and representatives involved in a Product Discovery phase would look like this:
Product Owner (PO).
Project Manager.
Business Analyst.
Solutions Architect.
UX Designer.
Programmers.
Quality Assurance Testers.
Representative End Users.
In theory, these should be the members involved in this phase.
In addition to this, UX (user experience) specialists can be extremely helpful in the Discovery process, as many functional limitations can be informed by user interface (UI) requirements.
Better integration of the design department with the Discovery processes in Software Development can be achieved through a design thinking workshop, where stakeholders meet to comprehensively discuss the project’s motivations, requirements, and vision.
Product Discovery Process
In order to design a Product Discovery process, the initial needs must be known. At least one initial meeting should be held with the development team so that the project can be presented to everyone, and any specific questions about the client and the project may be raised in a collaborative environment.
Keep in mind that this process can last from a few days to a few weeks, so there is no list of steps to design the ideal process; this makes each application, idea, and team unique, and the process must be able to adapt to their needs at the time.
However, Huenei IT Services focuses on developing the best products for your company, this is why we’ve decided to share the following steps that could help you create your Software Discovery process:
1. Discover the purpose of software development
This first activity focuses on the “why”.
As we begin the digital product development phase, we ask ourselves what the ultimate goal of the project is. We can’t build a great product if we don’t know why we are building it in the first place. By understanding everyone’s expectations, we discover the motivations and context required to make focused decisions during the project execution.
2. Get an overview of the business
The next step is to analyze the business model of the application and understand the company behind it.
We see this as a critical time to understand how the idea of this application came about, what the company is like, and how this product will help the company grow.
3. Define the metrics
The main question in this third step is how to measure the success of the product after development.
When setting a timeline, the idea is to identify milestones and criteria to measure the product’s success.
Goal setting methodologies are great options to deepen the discussion.
4. Set the restrictions
At this stage, the conversation becomes more realistic.
Now we all know that resources are not unlimited, and that creates a scenario where each project has its limitations, such as a restricted investment or a close launch date.
That is why we believe that it is important to know which restrictions are the most important and which allow for more flexibility.
5. Identify the risks
Moving on, our goal here is to identify the risks worth worrying about, so that we can focus on those that are not out of our reach.
Just as important as listing the things that could go wrong with the project is recognizing that we can handle some risks, but not all; what these risks are and which of them could mean a leak point of resources, including time.
6. Understand the users’ needs
The questions in this step are related to the end-users of the application: Who are they? By discussing our ideal user and what this individual would be like, we can list how we imagine they would interact with the software.
This process is a great instance for the team to come up with a user interface (UI) that is suitable for those users.
7. Define work agreements and processes
Now is the time to define how the flow of the software development process will work.
At this stage, the team can agree on a work methodology, schedule checkpoints and other meetings, define responsibilities and work arrangements to make sure everything is clean and ready to go.
8. Finally, build a story map
The story mapping technique presented by Jeff Patton is a clear way to see the entire user journey that the application provides.
In fact, knowing about Discovery in Software Development will allow you to establish a necessary approach for efficient and timely development; being clear about this from the beginning means dealing with the abundant uncertainty at the beginning of any project, that is why communication, research, and analysis are key factors in solidifying the goal and defining the direction of the product development process, as well as discovering its obstacles and risks.
Conclusion
A properly planned and implemented Discovery is vital not only for the client but also for the development company in charge of the work. This not only allows teams to meet the set times and resources but also identify end-users’ needs and build a product/service that best meets their demands.
Please visit our Software Development expertise section for more information about our development practices.

by Huenei IT Services | Dec 1, 2020 | Software development
In the previous article, “Introduction to Business Blockchain”, we learned about this technology, its main characteristics, and benefits, along with its classification and a few consolidated use cases. On this occasion, we will learn about the technical aspects that define it and briefly introduce five of the main platforms available for the implementation of Enterprise Blockchain solutions.
Blockchain
The name Blockchain stems from the data structure, where a series of transactions are grouped into sequentially chained blocks. Without going into the details of a particular implementation, each block is usually made up of an index (1, 2, 3, n), a timestamp (date and time of creation), data (transactions or small programs called smart contracts), a field called a nonce (number only used once) obtained through consensus, and two hashes (fixed-width alphanumeric representation, obtained by applying a cryptographic function), one from the previous block and one pertaining to the block itself.
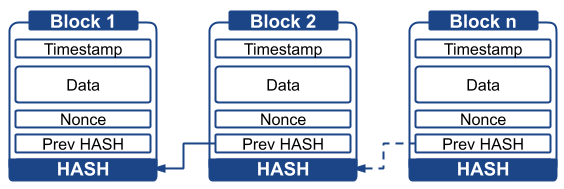
The calculation of a hash is a simple mathematical operation that provides an unrepeatable result, from which it is impossible to reconstruct the source information. Thanks to the inclusion of the previous hash in the current block, any modification or elimination of a block automatically invalidates the following ones, hence blocks can only be added.
Peer network and consensus
Blockchain networks are always distributed and peer-to-peer (P2P). Instead of relying on a central server, the computers are directly connected to each other. Each member contributes to the computing power (consumed to create consensus) and storage. This technology is considered more secure than a centralized network, since there is no single point of attack, and it also offers 100% uptime (the network stays up as long as members are connected).
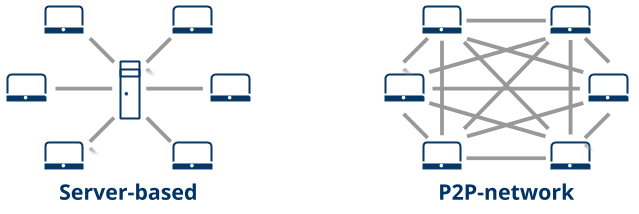
The information sent to be added to the chain is cryptographically signed by a private key and is accompanied by the corresponding public key so that the members of the network can verify its origin. To consolidate as a new block, the parties must agree to use a consensus protocol, which ensures that the chain is the same in each node and that there are no malicious actors manipulating the data.
Consensus protocols are mechanisms used for the members of a blockchain network to come to a consensus. In public and open networks, such as Bitcoin and Ethereum, computationally complex protocols are used, one of the best being Proof-of-work (PoW). Basically, in addition to the chain being extremely difficult to modify (it is necessary to understand in detail how it works and have control of at least 51% of the network), the purpose of the system is that anybody who intends to modify it finds it totally unfeasible to even try (it requires specialized equipment, based on devices such as GPUs or FPGAs, plus the major power use required to recalculate the blocks’ hash).
Smart Contracts
Smart Contracts are if … then style programs that are saved and executed by the blockchain. They get their name from legal principles, and they are intended to secure automated transactions upon meeting certain conditions in a safe way, avoiding possible malicious human actors.
There are specific languages, such as Solidity and Vyper, and more general ones, such as Golang, Node, and Java. Support for these languages varies from platform to platform, and some don’t support them at all, usually the ones made for cryptocurrency.
Main Enterprise Platforms
The implementation of a blockchain at the computer program-level takes considerations regarding the security, performance, and scalability of the system to the extreme. It is highly unlikely, and not recommended if the goal is not to create a new alternative, to encode from scratch. Instead, hundreds of free platforms are available and ready to be implemented, a remarkable feature gave the security and transparency they must provide. While many are intended for cryptocurrencies, enterprise platforms also exist. A brief description of five of the most popular platforms for this purpose is included below.
Ethereum: introduced in late 2013, and deployed for use between 2015 and 2016, it is one of the more mature alternatives. It was one of the first platforms to separate the blockchain concept from the particular case of cryptocurrencies, introducing the concept of Smart Contracts. It has its own currency, ETH, and is ideal for carrying out decentralized applications on public networks; but also, despite its lack of permits, it is widely used in business environments. It is backed by the Ethereum Enterprise Alliance (EEA, created in 2017), a non-profit organization with over 200 members, including companies among the 500 largest in the world, academic institutions, start-ups and Ethereum-based solution providers.
Hyperledger Fabric: Hyperledger is a Linux Foundation project launched in late 2015 that brings together enterprise blockchain developments. Its best-known member is Hyperledger Fabric, initially developed, and later donated, by IBM. It is strongly permissioned and private, to the point of allowing communications between two members of the network. Due to its business focus, it uses lighter consensus protocols, allowing a greater number of operations per second. Its first version for production, 1.0, is from mid-2017, with 2.0 released in early 2020.
Ripple: it is rooted in a pre-Bitcoin project, thus presenting some distinctive technical characteristics. It emerged as a platform in 2012, mainly for financial uses, with the main banks among its users. It is based on the use of a cryptocurrency, XRP, and unlike the main modern platforms, it does not support Smart Contracts (they are being added at the end of 2020).
Corda: launched in 2016 by the R3 consortium, made up mainly of financial institutions. It is permissioned and has no associated currency. Its first stable version is from 2017, and it was strongly focused on banking, although over time other uses emerged.
Quorum: a development of J.P. Morgan, announced in 2016. Basically, it is a variant of Ethereum focused on the business world, where the consensus mechanism was replaced by a faster one, and permissions were added. In the middle of 2020, it was transferred to ConsenSys, a provider of Ethereum-based business technology solutions.
Conclusions
Thanks to its data structure, the type of distributed network, the cryptographic treatment, and the use of consensus, this technology boasts immutability, traceability, and security. As for the development of Smart Contracts, it requires specific knowledge about the platform where it will be executed, knowing how to interact with its API, and getting used to a new programming paradigm. Aside from the different platforms available, the business world seems mainly divided between Ethereum and Hyperledger Fabric, with the former more focused on B2C (Business to Consumer) and the latter on B2B (Business to Business).
The main difference lies in whether the network is public and non-permissioned, or private and permissioned. To decide whether to implement one or the other, the possible need for coin consumption must be taken into account for the first case; for the second case, based on the knowledge about the members that become registered and identified entities in the network, lighter consensus protocols can be used, which increases the possible number of operations per second.

by Huenei IT Services | Nov 15, 2020 | Software development
Bitcoin, the cryptocurrency that began operating in early 2009, is the first implementation of what is known as Blockchain: a digital ledger, distributed and incorruptible, able to record all valuable information. After it became independent as a technology between 2013 and 2015, and thanks to the added execution of small programs called Smart Contracts, new use cases emerged. Around 2017, permissioned private versions, designed for the business environment, were launched. In 2020, the top implementations are at least in their second generation, with established use cases, several proposed, and many to discover.
While the term is being widely used along with revolutionary promises in many fields, exaggerated in more than one case, it is clear that this is a technology worth taking into account and one that we should leverage. Its main benefits include immutability (impossibility of changing the recorded history), traceability, and security, allowing users to eliminate intermediaries, accelerating times, and reducing costs.
Overview
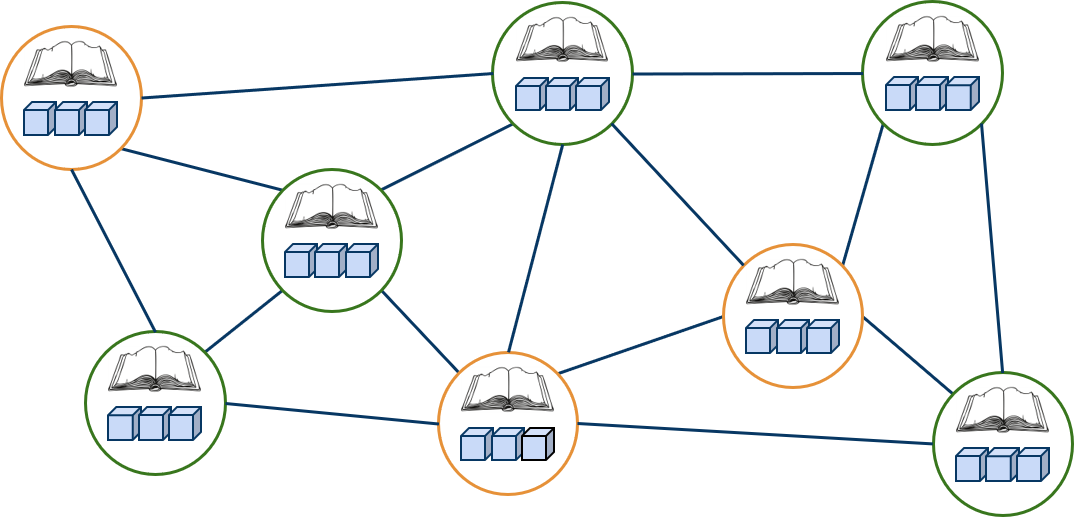
A blockchain is a sequential data structure, replicated in a cryptographically secure peer-to-peer network made up of blocks that can only be added through consensus among its members.
Changing the network status involves grouping data into units known as blocks. These can only be added, they include a timestamp and are mathematically validated against all previous blocks. Any attempt to delete or modify a block invalidates all subsequent ones. This mainly ensures the characteristics of immutability and traceability.
By using a peer-to-peer network, instead of relying on a central server prone to attacks or downtime, members can communicate with each other to mathematically agree on the new state of the network. This mechanism and the intensive use of cryptographic techniques provide an unprecedented degree of IT security. Along with an ability to break the cryptography and control at least 51% of the network members, and alteration attempt would require a computing power capable of reconstructing the new state of the network, all of which would render the task unfeasible and inconvenient.
Classification
Blockchain networks can be public or private, with or without permissions, thus creating the following main categories:
- Public, not permissioned: anyone can participate and all the information is openly available. It is the preferred option for the implementation of cryptocurrencies and distributed applications (where transparency is provided and censorship is avoided). These networks use greater computational complexity, which makes them slower. There is no owner.
- Public, permissioned: each participant’s identity is verified to grant access, but all information is openly available to participants. It is usually used in voting systems and is implemented by a consortium of public and private actors.
- Private, permissioned: each participant is verified and approved. It is usually the preferred business option. The owner of the implementation is a company or a small group of companies. Mathematical complexity is decreased based on the reduced number of participants and their permissions, so the network is much faster. Some reach the granularity of creating specific channels between two participants, without affecting the mathematical security provided by the network.
Considerations
A blockchain is at the backend of an application, taking the place of a traditional database. Since its storage capacity only increases, and it is also replicated in all the members of the network, it is recommended to keep only what is strictly necessary, using a database for everything else.
You don’t need a blockchain per se, but you need the solution to a problem that could eventually lead to its implementation.
As two key points to decide on its implementation, users should analyze whether there will be different actors first, and if so, if more than one will be granted writing permission. If both conditions are not met, there are simpler solutions. A good reason for implementation is the need to eliminate intermediaries, allowing two or more parties to interact relying on the blockchain.
If trust is not an issue, the use of blockchain does not represent any advantage over a database.
Use cases
- It is possible to detect some common usage patterns, including:
- Decentralized Finance (DeFi), through a secure platform for making optimized payments, executing insurance, etc.
- Digital asset management, for the exchange of all kinds of goods between individuals or entities, such as tickets to shows, loyalty program points, real estate, etc.
- Supply chains, for the complete traceability of any product, from the producer to the final consumer, whether it be raw materials, food, or medicines, in the case of Pharmacovigilance. IoT (Internet-of-Things) devices are also commonly used for automated registration in different stages of a workflow.
- Governance, with the implementation of Citizen Identity systems, elections, budgets and public tenders to increase the efficiency, quality, and transparency of the State.
- Management of Intellectual Property, creating a record of the date, time, and authorship as reliable evidence certifying this data.
- Certified information of all kinds, ensuring its veracity, for example, University degrees.
Secure data sharing, centralizing information and allowing access to it to those who need it, for example, medical records or research data.
Conclusions
As a concept, blockchain is relatively new, with its first implementation (Bitcoin) in 2009, its opening to other uses in 2015, business versions emerging in 2017 and multiple proofs of concept in 2020. However, it involves the combination of multiple technologies that have been around for a long time and were creatively combined in a platform with disruptive uses.
Some consider that hearing the word “Blockchain” today is like talking about the Internet in the mid-90s, and we are reminded about the way the Internet transformed the world we live in for business, commerce, communications, and media. In fact, public blockchain networks are often compared to the Internet, while private networks would be more of a synonym for Intranet.
Without having to be certain about the future, it is clear that it is a tool worth knowing, mastering, and using. Not only does it add value and security in well-known use cases, but it also opens the door to new opportunities. Furthermore, in our currently globalized world, it is a matter of time before having to join an existing network will require the use of this technology. Huenei can help your business by providing Consulting, Network Architecture Design, and Application Development services, from the planning and definition of requirements to the final project deployment phase.
