

Data Lakes en AWS
Introducción
En el artículo Conceptos clave sobre Data Lakes, hablamos sobre su importancia, arquitectura y los comparamos con un Data Warehouse. En esta entrega, nos enfocaremos en su implementación usando Amazon Web Services (AWS), la plataforma cloud de Amazon. Veremos el flujo general, los distintos servicios disponibles y, por último, AWS Lake Formation, una herramienta especialmente diseñada para facilitar esta tarea.
Flujo general
Un Data Lake respalda las necesidades de nuestras aplicaciones y analíticas, sin que debamos preocuparnos constantemente por el aumento de recursos de almacenamiento y cómputo, a medida que la empresa crece y la cantidad de datos aumenta. Sin embargo, no existe una fórmula mágica para su creación. Generalmente, implica el uso de docenas de tecnologías, herramientas y entornos. En el siguiente diagrama, se puede observar el flujo general de datos, desde la recopilación, el almacenamiento y el procesamiento, hasta el uso de las analíticas mediante técnicas de Machine Learning y Business Intelligence.
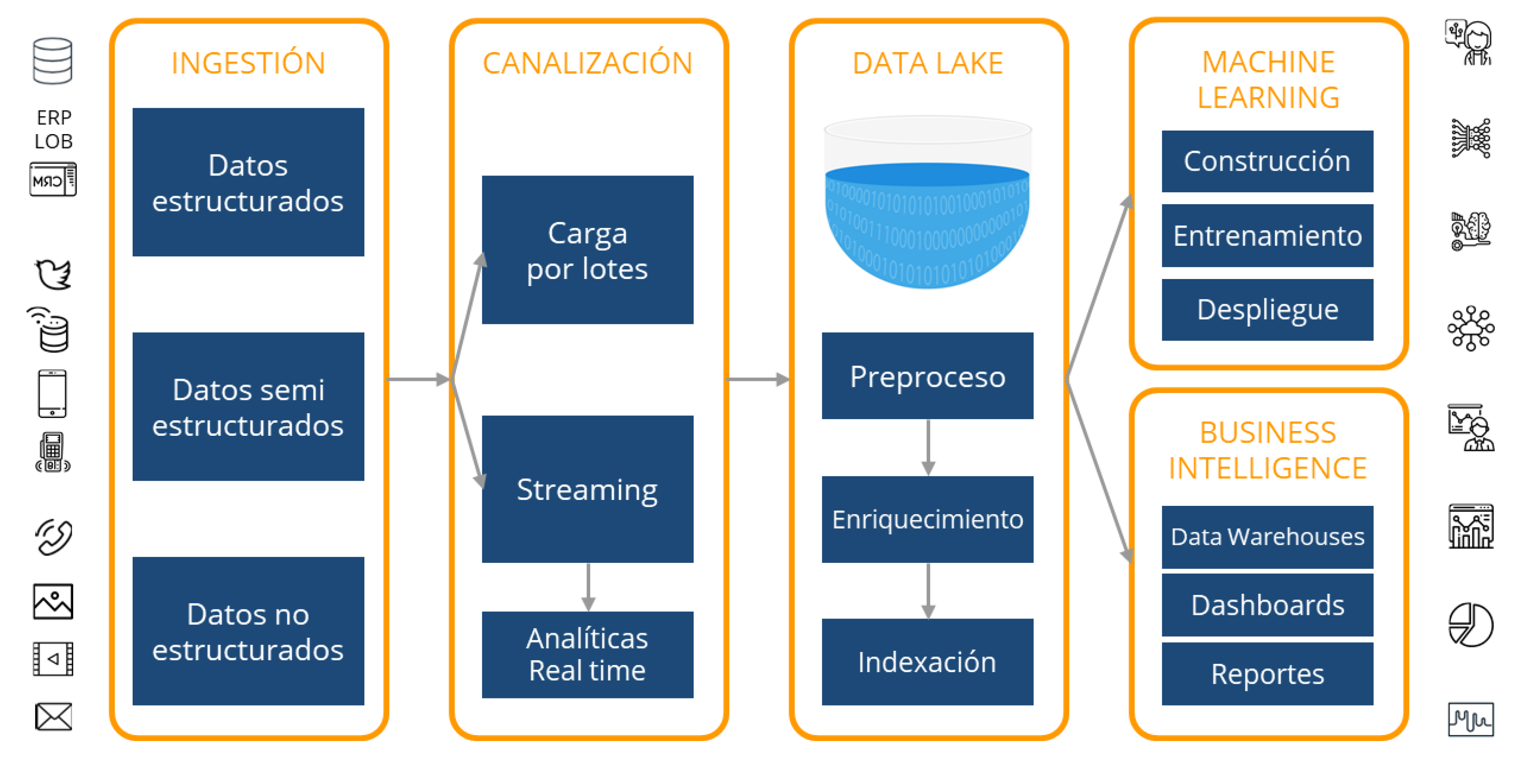
Servicios disponibles en AWS
AWS brinda un amplio conjunto de servicios administrados que ayudan a constituir un Data Lake. Es necesaria una planificación y diseño adecuados para migrar un ecosistema de datos a la Nube, y para ello es fundamental comprender la oferta de Amazon. Aquí haremos mención de solo algunas de las herramientas más importantes en cada etapa del flujo.
Ingestión
El primer paso es analizar los objetivos y beneficios que se desean lograr con la implementación de un Data Lake basado en AWS. Una vez diseñado el plan, se deben migrar los datos a la Nube, teniendo en cuenta el volumen de los mismos. Es posible acelerar fácilmente esta migración con servicios como Snowball y Snowcone (dispositivos edge para almacenamiento y cómputo) o DataSync y Transfer Family, para simplificar y automatizar transferencias.
Canalización
En este paso, se puede operar de 2 modos: por Lotes o por Streaming.
En la Carga por Lotes, se utiliza AWS Glue para extraer información de varias fuentes, en intervalos periódicos, y moverlos al Data Lake. Normalmente implica alguna transformación mínima (ELT), como la compresión o la agregación de datos.
En el caso de trabajar con Streaming, se ingieren datos generados continuamente a partir de múltiples fuentes, como archivos de logging, telemetría, aplicaciones móviles, sensores IoT y redes sociales. Se pueden procesar durante una ventana de tiempo circular y canalizar el resultado al Data Lake.
Las Analíticas en tiempo real brindan información útil para procesos de negocio críticos que dependen del análisis de datos en streaming, como algoritmos de Machine Learning para la detección de anomalías. Amazon Kinesis Data Firehose (servicio gestionado para streaming) ayuda a realizar este proceso desde cientos de miles de orígenes en tiempo real, en lugar de cargar datos durante horas y procesarlos luego.
Almacenamiento y Procesamiento
En un Data Lake de AWS el servicio más importante de todos es Amazon S3, que brinda almacenamiento de alta escalabilidad, excelentes costos y niveles de seguridad, ofreciendo así una solución integral para llevar a cabo diferentes modelos de procesamiento. Puede almacenar datos ilimitados y cualquier tipo de archivo como un objeto. Permite crear tablas lógicas y jerarquías a partir de carpetas (por ejemplo, por año, mes y día), permitiendo la partición de datos en volumen. También ofrece un amplio conjunto de funciones de seguridad, como controles y políticas de acceso, cifrado en reposo, registro, monitoreo, entre otros. Una vez que los datos se cargan, pueden usarse en cualquier momento y en lugar, para afrontar cualquier necesidad. Cuenta con una amplia gama de clases de almacenamiento (Estándar, Inteligente, Acceso poco frecuente), cada una con diferentes capacidades, tiempos de recuperación, seguridad y costo.
AWS Glacier es un servicio para el archivado seguro y la gestión de copias de seguridad, a una fracción del costo de S3. Las recuperaciones de archivos pueden demorar de pocos minutos a 12 horas, dependiendo de la clase de almacenamiento seleccionada.
AWS Glue es un servicio administrado de ETL y Catálogo de Datos que ayuda a encontrar y catalogar metadatos para realizar consultas y búsquedas más rápidas. Una vez que Glue apunta a los datos almacenados en S3, los analiza mediante rastreadores automáticos y registra su esquema. El propósito de Glue es realizar transformaciones (ETL/ELT) usando Apache Spark, scripts Python y Scala. Glue no tiene servidor; por lo tanto, no hay ninguna infraestructura configurada, lo que lo hace más eficiente.
Si se requiere una indexación de los contenidos del Data Lake, puede utilizarse AWS DynamoDB (base de datos NoSQL) y AWS ElasticSearch (servidor de búsqueda de texto). Además, mediante el uso de funciones AWS Lambda, activadas directamente por S3 en respuesta a eventos como la carga de nuevos archivos, pueden dispararse procesos para mantener su Catálogo actualizado.
Analíticas para Machine Learning y Business Intelligence
Hay varias opciones para obtener información de forma masiva del Data Lake.
Una vez que los datos han sido catalogados por Glue, se pueden utilizar diferentes servicios en la capa de cliente para analíticas, visualizaciones, dashboards. etc. Por ejemplo, Amazon Athena, un servicio serverless interactivo para consultas exploratorias ad hoc utilizando SQL estándar; Amazon Redshift, un servicio Data Warehouse para consultas e informes más estructurados; Amazon EMR (Amazon Elastic MapReduce), un sistema administrado para herramientas de procesamiento Big Data como Apache Hadoop, Spark, Flink, entre otras; y Amazon SageMaker, una plataforma de aprendizaje automático que permite a los desarrolladores crear, entrenar e implementar modelos de Machine Learning en la nube.
Con Athena y Redshift Spectrum, se puede consultar directamente el Data Lake en S3 utilizando el lenguaje SQL, a través del Catálogo de AWS Glue, que contiene metadatos (tablas lógicas, esquema, versiones, etc.). El punto más importante es que sólo se paga por las consultas ejecutadas, en función de la cantidad de datos escaneados. Por lo tanto, puede lograr significantes mejoras en el desempeño y el costo al comprimir, dividir en particiones o convertir sus datos en un formato de columna (como Apache Parquet), ya que cada una de esas operaciones reduce la cantidad de datos que Athena o Redshift Spectrum deben leer.
AWS Lake Formation
Construir un Data Lake es una tarea compleja, de varios pasos, entre ellos:
- Identificar fuentes (Bases de Datos, archivos, streams, transacciones, etc.).
- Crear los buckets necesarios en S3 para almacenar estos datos, con sus correspondientes políticas.
- Crear los ETLs que realizarán las transformaciones necesarias y la correspondiente administración de políticas de auditoría y permisos.
- Permitir que los servicios de Analíticas accedan a la información del Data Lake.
AWS Lake Formation es una opción atractiva que permite a usuarios (tanto principiantes como expertos) comenzar de manera inmediata con un Data Lake básico, abstrayendo los detalles técnicos complejos. Permite monitorear en tiempo real desde un único punto, sin necesidad de recorrer múltiples servicios. Un aspecto fuerte es su costo: AWS Lake Formation es gratis. Sólo se cobrará por los servicios que se invoquen a partir de él.
Permite la carga de diversas fuentes, monitorizar esos flujos, configurar particiones, activar el cifrado y gestión de claves, definir trabajos de transformación y monitorearlos, reorganizar datos en formato columnar, configurar el control de acceso, deduplicar datos redundantes, relacionar registros vinculados, obtener acceso y auditar el acceso.
Conclusiones
En estos 2 artículos, conocimos que es un Data Lake, qué lo hace diferente a un Data Warehouse y cómo se podría implementar en la plataforma de Amazon. Es posible reducir significativamente el CTO moviendo su ecosistema de datos a la nube. Proveedores como AWS agregan nuevos servicios continuamente, mientras mejoran los existentes, reduciendo los costos de los mismos.
Huenei puede ayudarlo a planificar y ejecutar su iniciativa de Data Lake en AWS, en el proceso de migración de sus datos a la nube y la implementación de las herramientas de Analíticas necesarias para su organización.